

DynamoDB?
DynamoDB는 Amazon Web Services(AWS)에서 제공하는 NoSQL 데이터베이스 서비스입니다. 방대한 양의 읽기 및 쓰기 처리량을 처리하도록 설계된 완전 관리형의 빠르고 유연한 데이터베이스 서비스로. 기존 RDBMS와 달리 DynamoDB는 데이터를 분산 방식으로 저장하므로 수평 확장이 가능합니다.
이번 글의 주제는 사용자의 요청에 따라 대량의 데이터를 필터링하여 가져오는 방식이 필요한 경우이므로 DynamoDB의 Scan과 Query 두 가지 방식에 대해 다루려 합니다.
DynamoDB의 Scan?
DynamoDB의 Scan은 테이블 또는 보조 인덱스에서 모든 항목을 검색하는 데 사용됩니다.
Scan은 테이블의 모든 데이터를 반환하므로 특히 테이블의 데이터가 많을 경우 시간과 리소스를 많이 사용할 수 있습니다.
Scan 사용 CASE
Scan은 전체 테이블의 백업 수행 또는 다른 시스템으로 데이터 내보내기와 같이 테이블에서 모든 항목을 검색해야 하는 작업에 가장 적합합니다. 또한 전체 텍스트 검색, 데이터 필터링 및 집계를 수행하는 데 유용합니다.
Scan의 한계
Scan의 주요 제한 사항은 성능입니다.
데이터 양이 많은 대형 테이블 Scan은 속도가 느리고 상당한 리소스를 소비하므로 비용이 많이 드는 작업이 될 수 있습니다.
또한 Scan은 테이블의 모든 데이터를 반환하므로, 높은 네트워크 및 스토리지 비용이 발생할 수 있습니다.
응답속도가 중요한 실제 api서비스에서는 Scan 사용을 지양하고 있습니다.
DynamoDB의 Query?
DynamoDB의 Query 작업은 테이블 또는 보조 인덱스에서 특정 항목을 검색하는 데 사용됩니다.
Scan과 달리 Query작업은 지정된 조건과 일치하는 데이터만 반환하므로 더 빠르고 효율적입니다.
Scan과 Query 동작의 비교
Scan과 Query의 주요 차이점은 성능과 효율성입니다. Scan은 느리고 리소스를 많이 사용할 수 있는 테이블에서 모든 항목을 검색하는 반면, Query는 테이블에서 특정 항목을 검색하므로 더 빠르고 효율적입니다.
어떤 방법의 성능이 더 뛰어 날까?
일반적으로 Query는 Scan 작업보다 빠르고 효율적입니다. Query는 지정된 조건과 일치하는 데이터만 검색하므로 네트워크를 통해 전송되고 데이터베이스에서 처리되는 데이터의 양이 줄어듭니다. 반면 스캔 작업은 테이블의 모든 데이터를 검색하므로 시간과 리소스가 많이 소요될 수 있습니다.
DynamoDB를 경험했다면 당연한 이야기라고 생각하겠지만 이 글을 남기게 된 이유는,
DynamoDB의 DB설계에 따라 2가지 데이터를 가지고 오는 방법이 공식적으로 알고 있듯이
같은 데이터를 Partition Key의 구성만 다르게 하여 query 할 경우, 정말 Query의 성능 우위로 결과가 나올까를 테스트해보고 싶었습니다.
DynamoDB와 RDBMS의 차이점(DB설계의 중요성)
DynamoDB는 여러 면에서 기존 관계형 데이터베이스와 다릅니다.
- RDBMS(관계형 데이터베이스 관리 시스템)와 달리 DynamoDB는 SQL을 지원하지 않으므로 자체 쿼리 언어를 사용합니다.
- DynamoDB는 RDBMS에서 흔히 볼 수 있는 JOIN, FOREIN KEY 및 Stored Procedure를 지원하지 않습니다.
- 또한 DynamoDB는 스키마가 없습니다.
즉, RDBMS와 달리 데이터에 엄격한 구조를 적용하지 않기에 테이블 간의 연관관계를 지어 DB설계하지 않을경우 데이터를 가져오기 어렵다는 단점이 분명하게 있습니다. 제가 겪은 문제 역시 태그가 포함된 partition key가 테이블간의 relation이 없어 생긴 문제에서 비롯되어 지금의 테스트까지 오게 되었습니다.
데이터양이 많지 않다면 Scan도 좋은 선택지가 되지 않을까?
테이블의 크기가 커질수록 scan보다 query의 효율이 좋다는 것은 공식문서를 통해서도 충분히 확인할 수 있지만,
기존에 임시로 설계한 태그테이블은 단순이 partition key로만 구성된 테이블이었고 scan을 지양해야 한다면 db설계변경이 필요한 상황이었습니다.
그래서 데이터의 양이 많지 않을 때 기존 임시로 설계한 테이블 1의 Scan의 성능과 partition key를 임의 tag라는 string으로 설정하고, 기존에 partition key를 Sort key로 옮긴 변경한 테이블 2의 query성능이 실제로 얼마나 비용과 속도 및 성능에 퍼포먼스차이가 나는지가 궁금했습니다.

local의 node16 환경에서 테이블생성 및 아이템을 점진적으로 추가한 후 아래와 같은 코드로 테스트를 진행하였습니다.
각 테이블을 각각 scan과 query방법을 사용하여 아래의 요소를 비교했습니다.
1. 데이터 가져오기까지 시간
2. 데이터에 가져오기까지 소요한 capacity unit용량
3. 총 아이템 수
const start = async () => {
await Promise.all(['scan', 'query'].map((type) => getTagList(type)));
};
const getTagList = async (type) => {
switch (type) {
case 'scan':
console.time('Consumed Scan Time:');
const tagListByScan = await ddb.scan({
tableName: targetTableList.testTagTableByScan,
});
console.log('Returned Item:', tagListByScan.Count);
console.log('Consumed Capacity:', tagListByScan.ConsumedCapacity);
console.timeEnd('Consumed Scan Time:');
break;
case 'query':
console.time('Consumed Query Time:');
const tagListbyQuery = await ddb.query({
tableName: targetTableList.testTagTableByQuery,
options: {
KeyConditionExpression: 'pk = :pk',
ExpressionAttributeValues: {
':pk': 'tag',
},
ReturnConsumedCapacity: 'TOTAL',
},
});
console.log('Returned Items:', tagListbyQuery.Count);
console.log('Consumed Capacity:', tagListbyQuery.ConsumedCapacity);
console.timeEnd('Consumed Query Time:');
break;
}
};
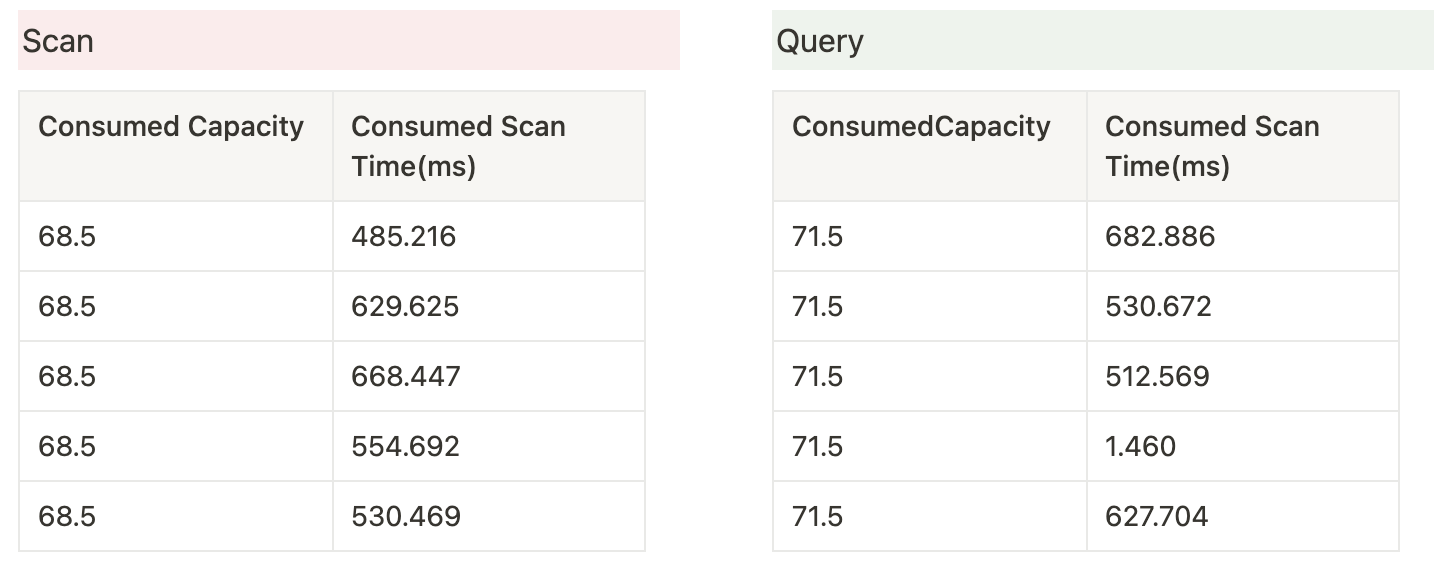
start();테스트결과는 다음과 같았습니다.


1000개가 넘어가는 구간부터는 소비용량이 query방식이 scan방식보다 좀 더 소모되는 것이 확인되었습니다.


결론
케이스를 좀 더 추가하여 데이터를 추출해볼해볼 필요는 있겠지만, 고유한 partion key값의 key설계변경을 통한 전체데이터 Scan과 Query 비교는 특정구간 이후 scan의 효율이 더 좋은 case가 다수 발생하는 것을 확인함으로써 아이템개수가 특정 개수를 초과하는 구간부터 Query가 성능, 비용이 Scan보다 무조건 좋다는 가설이 무조건 성립되진 않는다는 것을 확인했습니다.
현재 tag item의 개수가 물론 1천 개를 초과할 정도로 대량의 데이터로 관리될 가능성은 없으나, 향후 대량으로 관리될 데이터설계 시 DB설계의 중요성에 대해 좀 더 고민이 필요해 보였습니다.
테이블의 아이템수가 100개 이내인 경우 Query는 지정된 조건과 일치하는 데이터만 검색하므로, Scan보다 빠르고 효율적일 수 있습니다. 이렇게 하면 네트워크를 통해 전송되고 데이터베이스에서 처리되는 데이터의 양이 줄어들어 성능이 빨라지고 비용이 절감이 가능해 보였습니다.
하지만 테이블의 아이템수가 1000개 또는 10000개로 증가하면 Query와 Scan 간의 성능 및 비용 차이가 위의 결과처럼 전혀 다른 결과가 나타나는 것을 확인했습니다. 이 경우 쿼리 작업은 여전히 스캔 작업보다 빠르고 효율적일 수 있지만 설계에 따라 효율적이지 않을 수도 있다고 판단되었고 이런 상황에서는 보조 인덱스 비용 또는 데이터 검색 요구 사항의 복잡성도 고려해야 할 것 같습니다.
'AWS' 카테고리의 다른 글
| Next.js 정적 웹사이트 S3 + CloudFront + Route53 (가비아 도메인적용) (0) | 2023.09.08 |
|---|---|
| Next13 App router SSR(server side rendering) Amplify 배포 이슈(feat.슬랙에 배포알림 연동하기) (0) | 2023.08.24 |
| SSL/TLS 인증서 자동갱신이 되지 않을때 - AWS ACM, Route53 (0) | 2023.08.17 |
| [AWS Amplify Studio] - 초스피드 풀스택 서비스 만들기(React) (0) | 2022.06.24 |